Each action is defined using the script,
by specifying an action list containing
the (possibly compound) actions of which that particular
action consists.
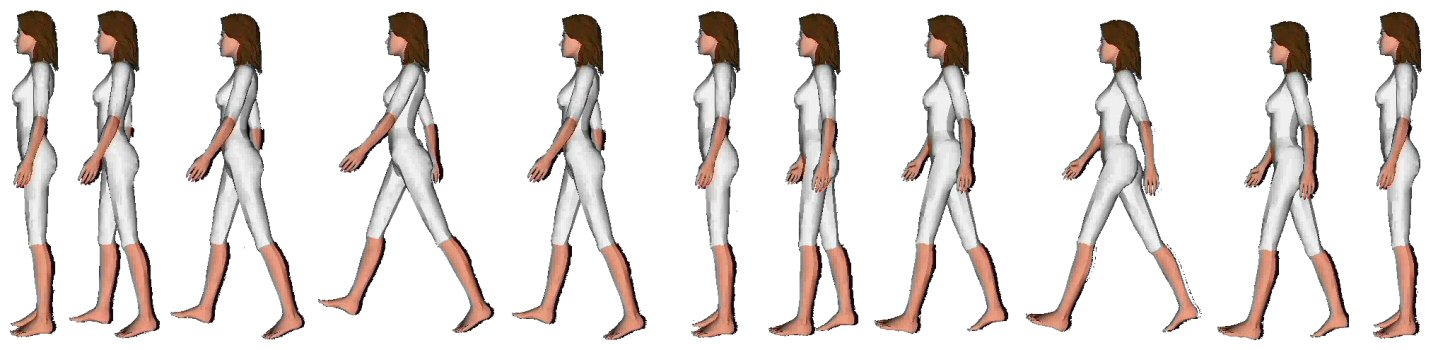
As an example, look at the definition of walking below.
example
script(walk(Agent), ActionList) :-
ActionList = [
parallel([turn(Agent,r_shoulder,back_down2,fast),
turn(Agent,r_hip,front_down2,fast),
turn(Agent,l_shoulder,front_down2,fast),
turn(Agent,l_hip,back_down2,fast)]),
parallel([turn(Agent,l_shoulder,back_down2,fast),
turn(Agent,l_hip,front_down2,fast),
turn(Agent,r_shoulder,front_down2,fast),
turn(Agent,r_hip,back_down2,fast)])
], !.

Notice that the Agent that is to perform the
movement is given as a parameter.
(Identifiers starting with a capital act as a logical parameter
or variable in Prolog and DLP.)
...
Interaction operators are needed to conditionally
perform actions or to effect changes within the environment
by executing some command.
Our interaction operators include:
test, execution, conditional
and until.
interaction
- test -- test(State)
- execution -- do(State)
- conditional -- if_then_else(State,Action1,Action2)
- until -- until(Action,State)
Potentially, an action may result in many parallel
activities.
To control the number of threads used for an action,
we have created a scheduler that assigns
activities to a thread from a thread pool consisting
of a fixed number of threads.
As a demonstrator for STEP, we have created
an instructional VR for Tai Chi,
the Chinese art of movement.
XML encoding
Since we do not wish to force the average user
to learn DLP to be able to define scripts in STEP,
we are also developing XSTEP, an XML encoding for STEP.
We use seq and par tags as found in
SMIL,
as well as gesture tags with appropriate attributes
for speed, direction and body parts involved.
As an example, look at the XSTEP specification
of the walk action.
XSTEP
<action type="walk(Agent)">
<seq>
<par speed="fast">
<gesture type="turn" actor="Agent" part="r_shoulder" dir="back_down2"/>
...
</par>
<par speed="fast">
...
<gesture type="turn" actor="Agent" part="r_hip" dir="back_down2"/>
</par>
</seq>
</action>
Similar as with the specification of dialog phrases,
such a specification is translated into the corresponding
DLP code, which is loaded with the scene it belongs to.
For XSTEP we have developed an XSLT stylesheet, using
the Saxon package, that transforms an XSTEP specification into DLP.
We plan to incorporate XML-processing capabilities in DLP,
so that such specifications can be loaded dynamically.
related work
There is an enormous amount of research dealing with
virtual environments that are in one way or another
inhabited by embodied agents.
By way of comparison, we will discuss a limited number of
related research projects.
As systems that have a comparable scope we may mention
[Environments] and DIVE, that both have a client-server
architecture for realizing virtual environments.
Our DLP+X3D platform distinguishes itself from these
by providing a uniform programmatic interface, uniform
in the sense of being based on DLP throughout.
The Parlevink group at the Dutch University of Twente
has done active research in applications of virtual
environments with agents.
Their focus is, however, more on language processing,
whereas our focus may be characterized as
providing innovative technology.
Both [Jinni] and [Scripts] deal with incorporating
logic programming within VRML-based scenes, the former
using the External Authoring Interface, and the latter
inline logic scripts.
Whereas our platform is based on distributed objects,
Jinni
deploys a distributed blackboard to effect multi-user synchronisation.
Our scripting language may be compared to
the scripting facilities offered by
Alice,
which are built on top of Python.
Also, Signing Avatar has a powerful scripting language.
However, we wish to state that our scripting language is
based on dynamic logic, and has powerful abstraction
capabilities and support for parallelism.
Finally, we seem to share a number of interests
with the VHML community,
which is developing a suite of markup languages
for expressing humanoid behavior.
We see this activity as complementary to ours,
since our research proceeds from
technical feasibility,
that is how we can capture the semantics of
humanoid gestures and movements within
our dynamic logic,
which is implemented on top of DLP.
future research
PRO
- high level platform -- flexible and powerful
- clean separation of concerns -- modelling and programming
CON
- added complexity -- due to hybrid platform
- performance penalty -- due to EAI communication
TODO
- models -- movement, behavior, moods
- mark up -- dialogs, actions, style
- support -- text-to-speech, interaction
www.cs.vu.nl/~eliens/research
In summary, we may state that our DLP+X3D platform is a powerful,
flexible and high-level platform for developing
VR applications with embodied agents.
It offers a clean separation of modeling and programming concerns.
On the negative side, we should mention that
this separation may also make development more complex
and, of course, that there is a (small) performance penalty
due to the overhead incurred
by using the External Authoring Interface.
Where our system is currently lacking, clearly,
is adequate computational models underlying humanoid behavior,
including gestures, speech and emotive characteristics.
The VHML effort seems to have a rich offering that we need
to digest in order to improve our system in this respect.
Our choice to adopt open standards, such as XML-based X3D,
seems to be benificial, in that it allows us to profit
from the work that is being done in other communities,
so that we can enrich our platform with the functionality
needed to create convincing embodied agents
in a meaningful context.
{kind=link}
{kind=link}